

Enterprise patch management has rapidly evolved from an obscure, intermittent IT chore into an indispensable capability underpinning organizational resilience. As cybercrime exploded into a trillion dollar shadow economy, sophisticated threat actors relentlessly exploit the slightest crack in our digital fortresses.
Recent sobering statistics paint this stark reality:
- 300,000 new malware strains emerge annually
- 4 billion records were breached in the first half of 2022 alone
- 70% of exploits leverage known vulnerabilities where patches exist
- 95% of successful attacks compromise systems missing patches over a year old
- 70-90% of exploits would be thwarted through prompt patching
Yet despite unassailable evidence that consistent patching represents our best barricade against incessant attacks, many organizations still approach it sporadically. This guide definitively details modern patching best practices to help security and technology leaders rationale, optimize and strengthen this crucial capability.
We will unpack insights across six key domains:
- Clarifying exactly what patch management entails
- Quantifying the astronomical risks of inadequate patching
- Demystifying the various types of patching tools and tactics
- Mapping out patch management processes end-to-end
- Comparing prominent solutions on the market
- Outlining 12 indispensable best practices
Let’s get started raising patching consciousness within your organization to match today’s unprecedented risk climate.
What Exactly is Patch Management?
Before evaluating solutions or approaches, we must level-set on precisely what patch management aims to achieve.
Patch management refers to the automated processes for acquiring, testing and installing patches or hotfixes in order to remediate vulnerabilities across software, operating systems, network devices, and other endpoints.
This entails extensive coordination across security, operations and infrastructure teams to ensure continuous hardening of systems against the latest known exploits.
The overarching goals of patch management include:
- Remediating security vulnerabilities by eliminating known holes that allow exploits
- Maintaining maximum uptime by fixing bugs and flaws that impact stability
- Streamlining patching by centralizing control through solutions that automate rollout
With outcomes encompassing both cyber resilience and operational integrity, consistent enterprise patching remains indispensable.
However, organizations face noteworthy challenges in executing effective patch management:
- Sheer volume of patches – thousands of vulnerabilities emerge annually
- Rigorous testing required to avoid conflicts or compatibility breakdowns
- Potential business disruption during patch installation – especially for mission-critical assets
- Consistently applying patches across complex, dynamic environments spanning old and new infrastructure
The stakes could not be higher for overcoming these hurdles. With skilled personnel and the right platforms, patch management can provide the foundation for securing global enterprises against looming threat landscapes.
Why Effective Enterprise Patch Management Matters More Than Ever
In earlier generations of technology, sporadic patching after major incidents may have sufficed. But in today’s climate of organized cybercrime and automated attacks exploiting new holes within hours, such reactive approaches spell disaster. Consider these driving imperatives:
Preventing Security Breaches
With $600 billion lost to cybercrime annually, enemies are laser focused on infiltrating our systems. Unpatched vulnerabilities represent the path of least resistance, enabling ~80% of breaches. Without prompt patching, organizations face immense financial, legal and reputational exposure.
Maintaining Uptime & Continuity
Beyond malicious attacks, flaws frequently impact system stability and reliability, causing crashes until remediated. With average downtime costs exceeding $300K per hour, patching prevents disruptive outages that paralyze operations and revenue.
Achieving Continuous Compliance
Regulatory policies like HIPAA, PCI, SOX and GLBA mandate consistent patching to harden systems and protect sensitive data. Non-compliance risks heavy fines upwards of $100K per violation instance.
Moreover, high-profile global cyber incidents like the Equifax breach (unpatched Apache Struts) and the notorious WannaCry ransomware attack which crippled Britain’s NHS health system (exploiting dated Windows holes) demonstrate the potent consequences of inadequate patching.
Exponential Attack Surfaces
Finally, today’s vast and growing heterogeneity of infrastructure spanning cloud, mobile, IoT and modern IT ecosystems multiplies vulnerabilities exponentially. Where previously a few servers may have necessitated patching, now thousands of network edges, endpoints and embedded devices require ongoing vigilance.
With such astronomical risks, costs and attack surfaces, reliable enterprise patching is truly mandatory, not optional. Later we will detail specific best practices for managing patching at scale in the modern environment. But first, let’s demystify the available approaches and tools.
Breaking Down Types of Patch Management
Myriad methods and software options exist for implementing vulnerability remediation processes. Each approach carries distinct tradeoffs organizations must weigh based on their resources, staff, scale and culture:
Manual vs Automated Patching
The most fundamental choice is whether an organization handles patching manually utilizing internal IT resources vs automated solutions that centrally orchestrate patching across the environment.
| Approach | Description | Key Benefits | Key Tradeoffs |
|---|---|---|---|
| Manual Patching | IT administrators manually test and install patches during maintenance windows, typically using native operating system update capabilities. | Fine-grained review over each update prior to deployment. Flexible timing of installations. | Extremely time/resource intensive with risk of missing updates or delaying installations too long. |
| Automated Patching | Specialized patch management software centrally handles patch acquisition, testing and installation scheduling based on admin-configured rules. | Hands-free ongoing patching after initial policy configuration. Ensures consistent rollout independent of IT bandwidth constraints. | Less granular human review of each individual patch prior to deployment. Some disruption risk configuring autonomous logic. |
While manual patching allows precision control, automation is a necessity for all but the smallest organizations in the face of surging volumes of exploits.
Software Updates vs Software Deployment
Patching tools fall into two broad categories – those focused specifically on software updates consisting of patches and hotfixes vs more expansive software deployment solutions designed to push any type of software package across the environment.
| Type | Description | Key Benefits | Key Tradeoffs |
|---|---|---|---|
| Software Update | Capabilities built into operating systems specifically focused on automating the testing and delivery of patches, hotfixes and updates | Tight integration with native operating system functionality. No additional infrastructure required. | Limited reporting/analytics compared to dedicated 3rd party tools. Specific only to the native OS itself. |
| Software Deployment | Broader tools that centralize deployment of any type of software – both updates/patches and applications. May integrate with sys management suites. | Single unified console for managing all software across systems and endpoints. Better supports modern CI/CD workflows. | Generally more complex and expensive solutions aimed at larger enterprises. Must integrate patch acquisition workflow. |
If pursuing a specialized patching solution, smaller organizations may find software updates adequate, while broader deployment tools offer Total cost of ownership should factor heavily in tool decisions.
Agent-Based vs Agentless Patching
Another key choice is whether a patching solution leverages agents installed on each endpoint to facilitate software management vs agentless scanners that perform remote patching of systems without any deployed footprint.
| Type | Description | Key Benefits | Key Tradeoffs |
|---|---|---|---|
| Agent-Based | Tools that utilize lightweight software agents installed on each endpoint device to enable granular centralized software control | Provides greatest degree of endpoint visibility, tracking and management. Critical for modern endpoints. | Requires installed agent footprint on each managed device which may require updates/maintenance. Marginally more complex. |
| Agentless | Scanner solutions that inventory assets and orchestrate software deployments remotely without installed agents | Faster initial deployment without touching individual endpoints. Won’t conflict with other endpoint agents. | Scanner can’t match agent management capabilities. Better suited for networks/servers than modern remote endpoints. Limited scalability. |
Determining endpoint visibility needs and change readiness will steer ideal agent vs agentless selection.
On-Premise vs SaaS/Cloud Delivery
A final pivotal choice – with major cost, staffing and infrastructure implications – is whether organizations pursue solutions deployed on-premise or delivered via the cloud.
| Type | Description | Key Benefits | Key Tradeoffs |
|---|---|---|---|
| On-Premise | Dedicated patching software installed and managed across internal IT infrastructure | Maximum configurability and data security assurances for larger organizations. No reliance on internet connectivity. | Requires extensive in-house infrastructure and IT resources to deploy, manage and update |
| SaaS/Cloud | Web-based patching solutions centrally hosted by the vendor and accessed online | Rapid deployment with no local IT overhead. Usage-based cost model. Easy to trial and scale. Leverages vendor-managed cloud infrastructure. | Ceded control over data and systems. Reliant on consistent internet connectivity. Potential availability/reliability concerns. |
While cloud solutions expedite getting started, complex enterprises typically adopt on-premise to enable greater control, customization, reliability and data security.
With core approaches clarified, we will now overview the end-to-end patch management workflow guiding the vulnerability remediation process.
Mapping the Patch Management Process Lifecycle
Implementing robust patch management requires coordinating an extensive lifecycle spanning asset discovery, vulnerability prioritization, controlled testing, automated deployments, verification checks, and analytics for continuous improvement.
While variations exist across solutions, effective enterprise programs centralize patching processes across these key phases:
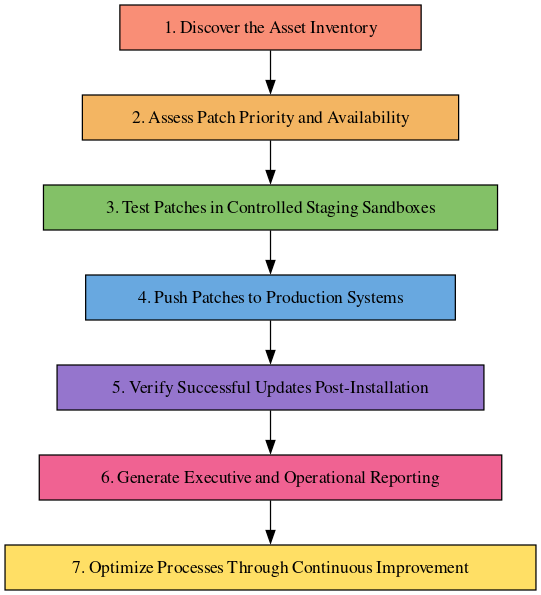
Let’s explore each step enabling smooth patch orchestration at scale:
1. Discover the Asset Inventory
The first imperative for reliable patching entails completely discovering assets across the environment requiring remediation. This foundational inventory enables assessing where the most critical vulnerabilities exist while serving as the prerequisite for all downstream processes.
Effective discovery requires cataloging this key information across servers, endpoints, appliances, cloud instances and other assets:
- Hardware Model Specifications – CPUs, memory, disks, vendors
- Operating System and Versions – Windows, Linux, iOS, Android
- Network Locations – Subnets, VLANs, sites
- Ownership and Functions – Business units, applications
- Sensitivity Classifications – Public, confidential, regulated
- Uptime Requirements – Backup availability, RTOs
- Existing Agents or Tools – Must coexist with new deployments
- Lifecycle Dates – Installations, planned migrations
This central inventory functions as the hub enabling many spokes of patch management – like risk analysis based on age or OS, enforcement reporting by group, triaging test queues and so on.
IT teams maintain comprehensive visibility through automated network scans encompassing appliances, servers, virtual instances and endpoints across on-premise and cloud sites. Supporting integrations with CMDBs, ITSM systems and directory services like Active Directory deepen insights further.
Querying this frequently updated system of record facilitates tailored patching policies across the staggered waves of infrastructure based on specifications, ownership, requirements and other factors.
2. Assess Patch Priority and Availability
With inventory established, administrators gain awareness of countless new patches and vulnerabilities daily from vendor notifications, blogs, threat intel feeds and tools monitoring releases.
Each raw disclosure requires structured assessment examining:
- Public Exploit Status – Weaponized in attacks or proof of concepts?
- Included in Threat Intel – Observed exploitations by adversaries?
- Severity Ratings – Using standards like CVSS 0-10 scores
- Affected Infrastructure Matches – Applies to internal assets?
- Remediation Difficulty – Simple confident fix or risky?
Leveraging resources like the National Vulnerability Database provides rich attributes assisting teams codifying severity benchmarks and asset applicability.
For example, a new remote code execution flaw in a popular server software may rank 9.5 CVSS and already have public proof of concept code along with entries in threat intel reporting – necessitating rapid prioritization. Conversely, a minor denial of service bug without current weaponization in niche software may deserve lower urgency handling.
Teams must align on a reliable vulnerability ranking methodology accounting for criticality so that available patches seamlessly flow into downstream patching pipeline stages without questions or debates delaying rollout.
3. Test Patches in Controlled Staging Sandboxes
However, before deploying updates into production systems, rigorously vet and test patches within segregated staging environments mirroring real configurations.
Sandbox labs facilitate substantial stress testing including:
- Functionality Testing – Validate intended changes operate without errors
- Integration Testing – Confirm interoperability with interconnected systems
- Performance Testing – Profile impacts on prevision, load capacity
- Failover Testing – Ensure resilience mechanisms engage properly
- Attack Simulation – Emulate threat behaviors and penetration test
Such testing surfaces compatibility issues or flawed patches requiring fix or delay. Analyzing sandbox findings determines if updates are cleared for automated rollout or need restrictions to groups, manual intervention or outright rejection.
For extreme publicly exploited threats like Log4J or ProxyLogon, limited testing in tightly controlled production pilot groups may be required – when attacks clearly overshadow disruption risks from changes.
Overall, investments in staging infrastructureConsistency, improvement cycles and skill building closing experience gaps all separate good programs from great.
4. Push Patches to Production Systems
Once sufficiently tested and approved, updates rollout through centralized orchestration servers facilitating smooth installation rather than relying on admin access to individual assets.
Capabilities like:
- Group-Based Targeting – Route to pre-defined segments
- Failure Handling – Auto-retries and flags
- Status Logging -Tracks individual asset completions
- Enforced Restarts – Forces when necessary
- Rollback Provisions – Reverts flawed patches
This enables Tailoring rollout cohorts based on update sensitivities, usage patterns and potential compatibilities facilitates measured deployments.
5. Verify Successful Updates Post-Installation
Upon rollout, teams double check logs and reports validating patches reached assets needing remediation without gaps or issues. Scan networks programmatically identifying outliers missing updates to diagnose root causes – whether from bad scans, inactive systems or misconfigurations needing correction.
Similarly scrutinize assets where updates mysteriously fail even after repeated attempts – signalling flaky devices requiring deeper operational review for resolution. Don’t blindly trust orchestration platforms generate universal successes without occasionally verifying integrity.
6. Generate Executive and Operational Reporting
Leading patching solutions produce status reports including:
Executive Views
- Security posture improvements
- Financial risk reductions
- Compliance and audit enhancements
- Efficiency optimizations
Operations Views
- Per-asset patching levels shown over time
- Enforcement statistics and trends
- Infrastructure-wide completion rates
- Windows since major updates
Reporting paints stakeholder pictures – whether assurance for anxious executives or granular benchmarks driving administrator improvements.
7. Optimize Processes Through Continuous Improvement
Finally, continually re-evaluate program effectiveness through metrics exposing opportunities like:
- Increasing Automation – Where sizable gaps in manual vs automated patching exist
- Legacy System Complexity Reductions – Transitioning outdated platforms to modern solutions
- Improving Security Posture – Eliminating unpatched assets through enhanced discovery capabilities
- Shortening Enforcement Cycles – Tightening schedules between vulnerability disclosure to remediation
- Upgrading Infrastructure – Introducing new systems with native integrations, scalability and redundancy
- Coordinating Vendors – Consolidating solutions for unified visibility and administration
Analyzing trends quarterly distills objective insights to enhance technologies, processes, reporting, resources, integration and all facets perpetuating the secure patch management machine.
Now that we have detailed core patch processes, let’s explore prominent solutions for delivering robust, reliable enterprise patching.
Top Patch Management Software Solutions
Selecting the ideal patch management platform represents a pivotal decision underpinning vulnerability remediation success. Myriad solutions exist – from venerable enterprises trusted for decades to nimble upstarts aiming to disrupt stagnant incumbents.
Navigating the crowded vendor landscape and feature checklists to find the best fit solution can perplex even seasoned technology executives. This guide surveys the patch management software market to assist organizations identify top solutions matching their unique environment, infrastructure and use cases.
We will analyze distinguishing capabilities and limitations across three solution classifications:
1. Robust Enterprise Suite Platforms – Heavy-duty tools leveraging integrated modules with deep functionality for large complex organizations.
2. Mainstream Feature-Rich Offerings – Full-featured products from established vendors offering the best blend of ease-of-use, flexibility and value.
3. Streamlined MSP-Oriented Options – Cloud platforms fine-tuned for managed service providers patching customer assets.
For each category, we overview distinguishing pros, cons, infrastructure requirements and best fit scenarios to guide selection.
Robust Enterprise Suite Platforms
Mature companies like Microsoft, IBM and SAP lead Gartner’s Magic Quadrant ratings based on the all-encompassing functionality built over decades responding to large customer demands. Their patching capabilities integrate tightly with change management, compliance and asset inventory modules.
Let’s analyze key enterprise solution strengths:
Microsoft System Center Configuration Manager (SCCM)
What Stands Out
- Unparalleled native integration managing Windows infrastructure
- Built atop innate OS update mechanisms like WSUS
- Central dashboard for all system configuration needs
- Broad capabilities beyond just patching
Key Considerations
- Substantial infrastructure requirements
- Steep learning curve
- Costly licensing model
- Reliant on heavy Microsoft technology stack
When It Works Best
Microsoft-centric organizations where simplicity of leveraging native capabilities outweighs more flexible multi-platform support.
IBM Tivoli Endpoint Manager (TEM)
What Stands Out
- Supports extensive array of devices and OSes
- Integrates security, help desk, reporting and automation
- Rigorous compliance-centric access controls
- Feature-packed albeit complex
Key Considerations
- Demands significant training and expertise
- Relatively costly TCO
- Often necessitates professional services
- Considerable infrastructure requirements
When It Works Best
Heavily regulated industries like finance and healthcare standardized on IBM stack seeking tight unified control.
SAP Solution Manager
What Stands Out
- Unparalleled patching automation for SAP modules
- Deep asset management and license tracking
- Integrated performance monitoring and diagnostics
Key Considerations
- Naturally requires SAP-centric environment
- Not lightweight – substantial infrastructure
- Significant professional services commonly needed
When It Works Best
SAP-based organizations seeking enhanced operations, administration and compliance around core platforms.
While these solutions focus more heavily on comprehensive IT systems management rather than exclusively patching, for large complex organizations leveraging stacks from enterprise mega-vendors, their integrated capabilities bring tremendous value with corresponding tradeoffs.
Next let’s survey flexible mainstream patching tools striking optimal balances of features and usability.
Mainstream Feature-Rich Patch Management Solutions
This market segment contains popular windows-friendly tools like ManageEngine, SolarWinds and Quest bolstered by incumbents like Ivanti and BMC offering the most balanced blends of functionality, operational management depth and ease of use based on extensive customer feedback.
Let’s analyze distinguishing elements of leading mainstream solutions:
ManageEngine Patch Manager Plus
What Stands Out
- Highly-rated for intuitive interface
- Broad heterogeneous platform support
- Flexible licensing based on assets
- Great repute for support experience
Key Considerations
- Occasional need for third-party modules
- Some limitations around Mac/Linux support
When It Works Best
Growing mid-market IT environments with mixed platforms.
SolarWinds Web Help Desk
What Stands Out
- Tight integration managing SolarWinds infrastructure stack
- Affordable pricing scaled to environment
- Streamlined cloud delivery model
Key Considerations
- Less customizable than open enterprise platforms
- Mostly operational not strategic insights
When It Works Best
SMBs heavily leveraging other SolarWinds tools across their stack.
Quest KACE
What Stands Out
- Intuitive interface with depth of controls
- Broad capabilities for Windows/Mac/Linux
- Integrates with AD, Office 365 and Azure
Key Considerations
- More limited scaling to large complex environments
- Less seamless compared to Quest’s SCCM plug-ins
When It Works Best
Mid-market organizations seeking enhanced cloud integration and Mac/Linux support.
Ivanti Patch for Endpoints
What Stands Out
- Powerful risk analytics and asset discovery
- Granular automated remediation policies
- Integrates into other Ivanti modules
Key Considerations
- Substantial infrastructure requirements
- Higher cost player aimed at large enterprises
When It Works Best
Larger Microsoft enterprises with complex change management processes.
BMC Helix Patching
What Stands Out
- Flexible agentless and agent-based support
- Integrated into broader systems mgmt stack
- Rich access controls and change integration
Key Considerations
- Requires deep familiarity with broader BMC portfolio
- Demands rigorous planning and expertise
- Relatively costly
When It Works Best
BMC-leveraging organizations seeking enhanced discovery and enforcement bolting onto existing stack.
For organizations lacking six-figure budgets but needing set-and-forget patching automation across thousands of Windows and mixed endpoints, these mainstream solutions offer administration simplicity unlocked through years of product refinement and customer feedback.
Next let’s detail specialized options fine-tuned for MSPs and lean teams.
Streamlined MSP-Oriented Patch Management Options
Rounding out the key market segments, MSP-focused solutions aim squarely at efficiently securing customer endpoints rather than attempting comprehensive infrastructure oversight like costly enterprise platforms. Let’s discuss the favorable pricing models and operational leanness attracting MSPs along with limitations.
NinjaRMM
What Stands Out
- Impressive breadth supporting Windows, Mac, Linux
- Custom reporting and dashboard options
- Transparent published pricing
Key Considerations
- Potential gaps leveraging broader stack
- Light on change control components
When It Works Best
MSPs who just need simple affordable multi-platform patching with monitoring.
PDQ Deploy
What Stands Out
- Generous free offering to try capabilities
- Superb support reputation
- Intuitive simple interface
Key Considerations
- Lacks enterprise infrastructure integration
- No native reporting or auditing
When It Works Best
Cost-conscious managed service providers or SMBs.
Addigy
What Stands Out
- Specialization securing Mac devices
- Integrates with environments like Jamf Pro
- Real-time visibility into fleet status
Key Considerations
- Obviously Mac-centric
- Relatively new market entrant
- Limited broader infrastructure support
When It Works Best
Organizations heavily invested in Apple ecosystems.
Kaseya VSA
What Stands Out
- Seamless integration across Kaseya IT stack
- Polished workflows for MSP efficiency
- Broad RMM capabilities
Key Considerations
- Demands using the Kaseya ecosystem
- Weaker general change controls
- Mostly Windows-focused
When It Works Best
MSPs leveraging the Kaseya suite who want integrated patching to round out existing RMM capabilities.
While enterprise tools focus on comprehensive infrastructure insight, MSP-oriented options prioritize rapid time-to-value securing customer endpoints. Just know their simplified software asset coverage and administration can necessitate supplemental tools in more complex environments.
Note Down:
Determining ideal patch management software involves balancing factors like current scale, future direction, in-house vs outsourced management model, compliance demands, flexibility tolerances, infrastructure heterogeneity, and budgets.
While hundreds of tools in some form address patching, the solutions analyzed constitute recognized mature leaders segmented by customer size and philosophy.
Within each group, weigh the pros and cons vs your needs. Play to organizational strengths leveraging integrated vendor stacks or opt for greater multi-platform support from best-of-breed publishers.
Match high-touch software to high-touch teams while automating maintenance where possible to empower talent supporting business objectives. Map expenditures to genuine threat levels revealed through risk analysis – rather than overspending reacting to headlines.
Now equipped with an extensive appraisal model encompassing goals, processes, solutions and key considerations – let’s establish core best practices to codify world-class patch management operations.
12 Indispensable Patch Management Best Practices
Implementing efficient, comprehensive patch management is crucial for securing infrastructure against surging threats. Based on real-world experience supporting thousands of organizations, we recommend adopting these 12 seminal best practices as the foundation for an effective program.
1. Institute Consistent Automated Patching Cycles
To ensure continuous hardening of systems, define standard intervals for automated patching cycles across endpoints based on asset criticality. Typical cadences include:
- Critical Assets – Patch weekly or even daily
- Highly Sensitive Assets – Patch every 2 weeks
- General Infrastructure – Patch monthly
- Supported Legacy Systems – Patch Quarterly
For example, internet-facing web servers may patch daily while internal back-office applications may address updates monthly. Adjust cycles to balance security, compliance needs and operational flows.
Also schedule regular monthly or quarterly windows for supplementary manual updates requiring reboots, testing or upgrades unsuited to automated rollouts.
Document these standard cycles in internal policies and configurations to ensure consistent compliance independent of administrative bandwidth.
2. Aggressively Automate Patching Procedures
The volume of vulnerabilities and limited windows for remediation necessitate enforcing aggressive automation to execute defined patching policies.
Configure centralized orchestration tools to scan assets, assess risks, import updates and install patches per admin-defined rhythms and rules. Automation both eases administrative pains and closes consistency gaps that manual execution can’t achieve.
When implementing, provide options allowing IT teams to selectively override default automation temporarily for assets needing special handling. Reasons may include update conflicts, inadequate testing timelines or coordination delays.
Analytics comparing manual vs automated update ratios help identify patches causing repeated breaks from automation. This funnels improvement opportunities.
Overall, aim to make general automation the default with occasional exceptions where flexibility serves the greater mission. Over time, driving towards 95% automated enterprise patching is achievable.
3. Maintain a Continually Updated Central Asset Inventory
The fulcrum enabling effective discovery, risk analysis and patching automation relies on maintaining a frequently updated central inventory cataloging critical details for all assets requiring ongoing updates.
For each device, capture specifications like:
- Hardware model
- Operating system and version *Assigned owner and business function
- Network location segmenting environments
- Custom configurations or in-flight changes
- Installation dates for lifespan analysis
- Sensitivity classification
- Required uptime and maintenance windows
- Existing endpoint tools or agents
Update this master list continuously via automated network scans that enumerate devices across all sites and subnets. Supporting integrations with CMDBs, ITSM systems and AD/LDAP deepen insights.
Querying this inventory source facilitates tailored patch orchestration across the ecosystem based on factors like OS, lifecycle status, ownership, location and redundancy requirements.
4. Prioritize Publicly Exploited “Zero Day” Vulnerabilities
In a world with thousands of known vulnerabilities and limited windows between disclosure and weaponization, organizations must pragmatically prioritize based on active threats.
Specifically, patches remediating publicly exploited zero day vulnerabilities should take immediate precedence for accelerated rollout given the likelihood of attacks leveraging these known weaknesses.
Conversely, remediations for older legacy gaps posing no imminent danger should queue in secondary waves to balance windows. Continually re-assess priority definitions based on threat intelligence sources spotting vulnerabilities incorporated into new attacks or malware kits.
Establish emergency change approval channels allowing rapid sign-off for exceptionally high severity updates needing expedited handling. Even initiating updates during lower-risk periods before formal approvals complete can defuse urgent threats.
5. Stagger Patch Distribution Windows
Given inevitable disruptions from updates requiring restarts, recycling, testing or verification, astute administrators stagger patching distribution across multiple fixed weekly windows targeting different endpoint groups to avoid organization-wide instability spikes.
For example, Mondays may patch development infrastructure, Tuesdays for marketing groups, Wednesdays accounting applications etc.
This smooths the ripples from maintenance turbulence rather than allowing them to converge into major standstills derailing broader operations. It also funnels lessons learned from earlier groups informing later patching successes.
Define maintenance periods based on usage patterns and designate groups across lines of business, network zones, functions or applications.
6. Test Patches Thoroughly Within Isolated Sandbox Environments
However, before deploying updates into production systems, subject them to substantial compatibility and integration testing within isolated sandbox environments mirroring real-world infrastructure.
Analyze issues surfaced to determine if delays in rollout are necessary due to flaws in a given patch or adjustments to legacy systems needed beforehand.
For extreme emergencies involving publicly weaponized zero days directly threatening security, limited testing in production may represent the lesser evil if attacks clearly overshadow disruption risks. But these exceptions underline why organizations must invest in staging environments enabling routine controlled testing to prevent reactionary infrastructure changes.
Combine sandbox infrastructure with security tools examining behavior of new patches when subjected to different attack stimulations using vectors extracted from threat intelligence sources. This facilitates incredible quality assurance.
7. Verify Successful Patch Installation Across All Assets
Following deployments, double check logs and reports to validate updates successfully installed across all intended assets without gaps. Scan network to identify any outliers missing patches and determine root causes for the oversight like scan failures, inactive systems or update blockers needing reconfiguration.
Similarly, closely scrutinize records for assets failing updates even after multiple tries to understand why certain devices resist reliable patching. Often outdated legacy platforms reject new patches due to hard incompatibilities with modern code.
These consistent verification processes ensure teams meet compliance controls around consistent remediation rather than blindly assuming smooth rollouts. Detailed analyses also provide intelligence to refine future patching success rates.
8. Report Ongoing Metrics Tied to Business Risk Reduction
To maintain continuous executive support and resourcing, don’t just report operational statistics on patching but translate key metrics into the language of enterprise risk reduction and resilience.
Illustrate achievements through metrics like:
- Percentage of known vulnerabilities addressed – Directly quantifies reductions in exposure
- Hours of prevented downtime – Financial benefit of uptime assurance
- Faster audit compliance – Reduced cycles demonstrating controls to auditors
- Improved security ratings – External validations from analysts on program maturity improvements
These measurable demonstrations of decreased organizational instability, along with softer reputational benefits, rationalize investments more successfully than statistics about scan counts and deployment throughputs.
9. Establish Dedicated Internal Patch Management Teams
Given tremendous effort effective enterprise patching entails, don’t disperse responsibilities across infrastructure teams as a secondary chore.
Instead dedicate full-time employee roles and specialized teams accountable for patching processes end-to-end. When made people’s primary function, they gain proficiency rapidly to circumvent issues through experience.
Centralization also improves consistency, reporting, focus on process refinement and tool expertise. Combined, this drives better vulnerability remediation outcomes long-term.
10. Strictly Control Administrative Access
To prevent unauthorized changes outside formal patching processes by well-intentioned but mistaken IT staff, strictly limit administrative access to only essential personnel through defined processes audited routinely.
Integrate credential vaulting solutions via CyberArk or BeyondTrust to enforce privileged access management across patch management tools, operating systems and individual assets.
Conduct quarterly entitlement reviews revoking dormant credentials to contingencies like staff turnover. Following separation checklists upon employee departures further bolsters security.
Control, audit and encryption of administrative access represents crucial elements underlying trust in automated solutions. Their integrity hinges entirely on preventing potential backdoor breaches by internal parties.
11. Foster Cross-Departmental Collaboration
Effective patching requires tight collaboration across IT operations, security, infrastructure and other groups in an organization. Define roles for each team based on purview:
- IT Operations – Orchestrates patch testing, schedules rollouts and tracks compliance
- Security – Prioritizes threats, analyzes exploits and penetration tests
- Infrastructure – Provisions and maintains patching systems, sandbox environments and backups
- Messaging – Communicates maintenance windows internally to minimize disruption
- Engineering – Scrutinizes patch code and identifies compatibility risks
This unified effort combines requisite skills for smooth end-to-end patching while distributing ownership across the units needing influence at different points in the process.
12. Continuously Optimize Over Time
Amid the constant treadmill battling newfound vulnerabilities, it remains essential establishing iterative continuous improvement cycles identifying opportunities to further optimize patching processes.
Analyze trends quarterly in metrics spanning speed of patching issue resolution, asset coverage, enforcement exceptions, manual vs automated ratios, stranded legacy systems, testing effectiveness and so forth.
Distill insights into a rolling roadmap prioritizing enhancements – like added automation triggers, reporting upgrades, infrastructure changes, budget reallocations or modified policies – addressing current capability gaps flagged by the analysis.
Revisit and revise the plan monthly as new threats emerge and priorities shuffle based on environmental shifts. Significant events like mergers, technology migrations or leadership changes warrant re-architecting approaches.
This institutionalization of periodic introspection ensures the patching machine constantly sharpens itself to meet evolving challenges rather than atrophying from legacy assumptions.
In Closing
And in an age where cybercrime rings generate over $1 trillion in damages annually – exploiting the slightest technological oversight to cripple economies – overlooking something as fundamental as patching is gross negligence.
Thankfully, modern patching capabilities have evolved enormously over the past decade to match soaring threats. Today’s solutions blend comprehensive asset discovery, risk-based prioritization, tested rollouts, compliance reporting and other key features to secure modern heterogeneous infrastructure.
With the recommendations in this guide, technology and security leaders finally possess the knowledge and tools needed to rationalize and unlock sufficient patching resources. The outcomes? Vastly reduced risk exposure, operational resilience, leadership confidence and assurance for auditors.
Although patching often feels thankless amidst urgent demands and transformative visions, it remains the single most potent cyber defense globally. Much like a meticulous sentry boringly scanning the fortress despite craving action.
With dedicated specialists, the right technology and ongoing optimization, patch management delivers an indispensable return-on-investment through continuous incremental hardening.
Now the only path forward is working together across teams pragmatically to close dangerous breaches across all facets of digital society. Transitioning from breakthroughs without foresight to innovation with insight. Patch by patch, we must seal this new frontier to thwart those aiming to unravel progress.
Onward!
Frequently Asked Questions
What are the biggest obstacles organizations face trying to maintain reliable patch management?
The most common challenges include lack of executive buy-in, inadequate tools and resources, complex change management bottlenecks, and coordination gaps between security and IT teams.
What risks justify urgent investment in patching improvements?
Preventable outages crippling operations, data breaches violating compliance controls, ransomware attacks paralyzing productivity, and brand damage eroding customer trust all rationalize immediate patch management advances.
Where should organizations focus first in improving patching practices?
Get leadership support, establish an asset inventory, implement continuous automated scanning, and rollout a basic vulnerability remediation solution. These basics enable managing the Gap to build a mature program over time.
What metrics best convey patching value to leadership teams?
Quantify financial risk reduction from breaches avoided, hours of prevented downtime, accelerated audit compliance, and improvements in security ratings or analyst maturity assessments.
How can organizations balance disruption risks while patching urgently?
Maintenance windows, sandbox testing environments, change approval controls and staggered deployments across groups help smooth rollout. Start conservatively then refine over time.
What resources will reliable enterprise patching require?
Consider specialized staff, updated tools, security team collaboration, executive communications, and some incremental infrastructure. The investments pay themselves back many times over through risk reduction.
Should organizations leverage agents or agentless patching?
Agents provide vastly greater visibility and control – especially for modern remote endpoints. Agentless works only for networked on-premise servers. As remote work expands, agents become mandatory.
What employees pose the greatest threat to patch management reliability?
Well-meaning but unauthorized IT staff circumventing change controls and installing updates or applications without testing or coordinating through proper channels.
Which software vendors emit the highest patching load today?
Microsoft by far due to Windows ubiquity. Then Adobe Flash, Java, Apple, Mozilla and Google Chrome – all requiring ongoing vigilance. Monitor vendor release notes for changes.
![Top 8 DSA Project Ideas in 2024 [With Source Code]](https://evuzzo.com/wp-content/uploads/2024/05/DSA-Project-Ideas-in-2024.png)

![Top 15 Software Engineer Projects 2024 [Source Code]](https://evuzzo.com/wp-content/uploads/2024/04/Top-15-Software-Engineer-Projects-2024-Source-Code.webp)

